IBM SPSS Statistics Base
IBM SPSS Statistics Base
SPSSの基本機能「Base」
SPSS Baseは、豊富な統計解析機能を持つIBM SPSS Statistics の基本ソフトウェアです。Baseにさまざまなオプションを追加することで多様な分析やデータ加工に対応。オプションは任意で追加できますが、Baseは必須ソフトウェアとなります。

- Baseだけでどの分析手法が使えますか?
-
データ入力、Excel読込み、データ加工機能、記述統計量、グラフの作成と編集、出力のエクスポート等の基本機能に加え、回帰分析、因子分析、クラスター分析、クロス集計表、t検定、一元配置分散分析、ノンパラメトリック検定、ROC曲線、検定力分析、メタ分析などが実行できます。
Base のみでできない例として、ロジスティック回帰分析(Regression)、生存分析(Advanced Statistics)、コレスポンデンス分析(Categories)、ディシジョンツリー(Decision Trees)、欠損値の多重代入法(Missing Values)などが挙げられます。
- Baseだけで多変量解析ができますか?
-
多変量解析は、同時に3つ以上の変数(変量)を扱う分析の総称です。Baseでは、重回帰分析、判別分析、因子分析、主成分分析、クラスター分析などの多変量解析に対応します。ロジスティック回帰分析やCox比例ハザードモデル、決定木分析などの手法は、Baseにオプション製品を追加する必要があります。
SPSS Baseの主要な機能
一般的な操作
- データのインポート:
SPSS形式、Excel形式、ODBC、CSV、タブ区切りなど多様なデータソースに対応 - データエディター:
スプレッドシート形式で、データを入力、編集、表示、データエディターのセル内に値/値ラベルを表示 - ダイアログ:
変数の名前とラベルの表示、並び順の指定、値ラベルのツールチップ表示 - ユーザー・インターフェース言語の切り替え:
英語と日本語の切り替えなど - データセットの保護:
パスワード設定、読み取り専用 - カスタマイズ可能なツールバー機能を選択
- テーブルの設定:
数値の書式、線種、線幅、列位置合わせ、背景/前景の網掛け、線の表示/非表示等を変更、行、列、ラベルの表示/非表示を個々に設定して、要点を強調表示 - 出力ビューア:
アウトライン表示、表題や脚注の追加、折り畳み表示 - ピボットテーブル:
テーブルの行変数や列変数の入替、層変数の指定、書式の変更、テーブルルックの適用 - エクスポート:
Word、Excel、PowerPoint、PDF、HTML形式などの外部ファイルへの保存 - シンタックス:
シンタックスの貼り付け、編集、Pythonスクリプトに対応
度数分布表や記述統計
- 度数分布表: 度数、パーセント、有効パーセント、累積パーセント
- 中心傾向: 平均、中央値、最頻値、合計
- 散らばり: 最大値、最小値、範囲、標準偏差、標準誤差、分散、パーセンタイル値
- 分布: 尖度、尖度の標準誤差、歪度、歪度の標準誤差
- 図表: 棒グラフ、円グラフ、ヒストグラム、正規曲線の表示
- 標準化: Z得点
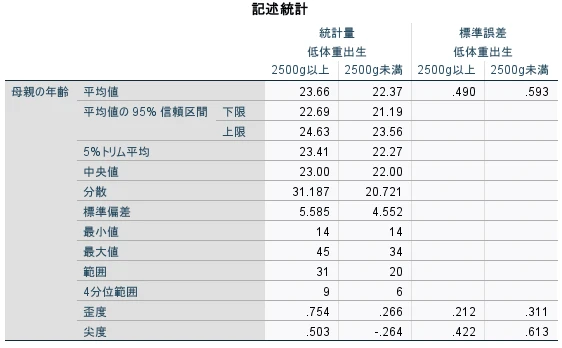
探索的データ分析
- 平均値の信頼区間
- 記述統計量: 四分位範囲、尖度、尖度の標準誤差、中央値、平均値、最大値、最小値、範囲、歪度、歪度の標準誤差、標準偏差、標準誤差、分散、5パーセントトリム平均値、パーセント
- M-推定量: Andrew のウェーブ、Hampel の M-推定量
- 極値や外れ値の特定、グループ別の出力
- グラフ: 箱ひげ図、ヒストグラム、幹葉図
- 正規性: Kolmogorov-Smirnov検定、Shapiro-Wilk検定、正規確率プロット、傾向化除去正規確率プロット
- Levene検定による水準と広がりの図: べき乗推定、変換、変換なし
グラフ機能
- 図表ビルダー: プレビュー表示を確認しながらグラフ作成
- 棒グラフ: 単純、クラスター、積み上げ、影付き、3-D効果
- 折れ線: 単純、多重、ドロップライン
- 面: 単純、積み上げ
- 円: 単純、分割の切り出し
- ハイロー:ハイロー・クローズ、差分、範囲棒グラフ
- 箱ひげ図: 単純、クラスター
- エラー・バー: 単純、クラスター、信頼区間、標準偏差、標準誤差
- 2重Y軸とオーバーレイ
- 散布図:
単純、重ね書き、散布図行列、3-D、適合線の使用: 線形回帰、曲線、信頼区間、垂直線、マーカー - 人口ピラミッド: 分布を左右に対応するように表示して比較
- ヒストグラム: 正規曲線の表示/非表示
- 品質管理図: パレート、X-Bar、範囲、シグマ、個別、移動範囲、CUSUM
- グラフテンプレート: グラフのレイアウトやデザインを保存して適用
- グラフのエクスポート:
BMP、EMF、EPS、JPG、PCT、PNG、TIF、WMF - 編集オプション:
並べ替え、値ラベル、フォント、色、格子線、基準線、凡例、表題、脚注、注釈など - 診断/探索チャート:
時系列プロット、自己相関/偏自己相関関数プロット、交差相関関数プロット、ROC曲線 - グラフボード: 変数の指定による適切なグラフを作成、ヒートマップ
- 関係マップ: 円、ネットワーク、グリッド
- ヒートマップは作成できますか?
-
はい、Baseに含まれる標準機能として「グラフボード」で作成可能です。
- グラフのデザインをテンプレート化することはできますか
-
はい、可能です。一度作成したグラフを編集し、デザインを保存してテンプレートとして適用できます。
クロス集計表
- 度数: 観測度数、期待頻度、周辺度数
- パーセント: 列、行、合計
- 残差: 非標準化残差、標準化残差、調整済み標準化残差
- 独立性の検定: Pearsonの漸近有意確率、Yates補正、尤度比、Fisherの正確確率検定(2×2クロス集計表)
- McNemarの検定、Cochran-Mantel-Haenszel統計量
- 名義尺度の連関: CramerのV、ファイ、GoodmanとKruskal のラムダ、タウ、不確定性係数
- 順序尺度の連関: GoodmanとKruskal の Gamma、Kendallのタウb、タウc、SomersのD、Spearman
- 一致の測定: Cohenのカッパ
- 相対リスク推定: リスク比、オッズ比、信頼区間
- 昇順または降順で表を表示、整数/非整数の重みが使用可
- 層別や多段クロス集計表は作成できますか?
-
層別クロス集計表は、層変数の指定により作成可能です。複数の変数を積み上げる多段クロス集計表はBaseの機能では対応しておらず、Custom Tablesオプションを追加することで作成可能です。
- Fisherの正確確率検定は対応していますか
-
2行2列のクロス集計表の場合は、カイ2乗検定を実行すると自動的にFisherの正確確率検定が実行されます。それより行数や列数の多いクロス集計表を対象にする場合は、Exact Testsオプションの追加で対応します。
平均の比較
- セル: 度数、平均、標準偏差、合計、分散
- 1サンプル: 1サンプルのt検定
- 独立サンプル: 独立サンプルのt検定、Welch検定
- 対応サンプル: 対応サンプルのt検定、ペア間の相関係数、平均値間の差
- 統計: 信頼区間、度数、自由度、平均値、両側有意確率、標準偏差、標準誤差、t統計量
一元配置分散分析
- 手法: 1元配置分散分析、Brown-Forsythe検定、Welch検定
- 出力: 分散分析表、自由度、平方平均、F比、有意確率
- 固定効果: 標準偏差、標準誤差、95%信頼区間
- 変量効果: 分散成分推定、標準誤差、95%信頼区間
- 記述統計量: 最大値、最小値、平均値、ケースの個数、標準偏差、標準誤差、95%信頼区間
- 等分散性検定: Levene検定
- 対比: 線形、2 次、3 次、それ以上の次数、またはユーザー定義
- その後の検定: 最小有意差、TukeyのHSD、Scheffé、Dunnett、Bonferroni、Sidak、HochbergのGT2、Tamhane のT2、Tamhane のT3、Games&Howell、その他
ノンパラメトリック検定
- カイ二乗: 期待範囲と頻度を指定
- 2項: 2分割(データからまたは分割点)および検定比率の定義
- ラン: 分割点の指定(中央値、最頻値、平均値、またはユーザー指定)
- 1サンプル: Kolmogorov-Smirnov、一様、正規、Poisson
- 2個の独立サンプル: Mann-Whitney検定、Kolmogorov-SmirnovのZ、Mosesの外れ値反応
- k個の独立サンプル: Kruskal-Wallis検定および中央値
- 2個の対応サンプル: Wilcoxon符号付順位検定、符号検定、McNemar検定
- k個の対応サンプル: Friedman検定、KendallのW、CochranのQ検定
- 記述統計量: 最大、平均値、最小、ケースの個数、標準偏差
2変量
- 相関係数: Pearson積率相関係数、Kendall、Spearman順位相関係数、片側および両側有意確率
- 偏残差: 偏相関係数、片側および両側有意確率
- 出力: 相関を行列として下三角または矩形相関行列に表示
- 距離: ケース間または変数間の近似値を計算
- 非類似度: ユークリッド距離、平方ユークリッド距離、カイ2乗、Chebychev距離、その他
- 類似度: Pearsonの相関、コサイン、その他、散らばり類似度、4分点相関
回帰分析
- 手法: 強制投入法、変数増加/減少法、変数増加ステップワイズ法、R2乗の変化量
- 記述統計量: 相関行列、平均値の交差積和、平均値、標準偏差、分散
- 出力: 分散分析表、回帰係数、回帰係数の標準誤差、標準化回帰係数、t値、回帰係数の95%信頼区間、Durbin-Watson
- 共線性の診断: 条件指標、固有値、許容度、VIF
- グラフ: ヒストグラム、正規確率、偏残差、外れ値、散布図
- 予測値: 非標準化、標準化、調整済み、平均値の標準誤差
- 距離: Cookの距離、Mahalanobis の距離、てこ比
- 残差: 非標準化、標準化、スチューデント化された、削除、スチューデント化された削除
- 影響力の統計: dfbeta、標準化dfbeta、dffit、標準化dffit、共分散比
- オプション: 投入と除去の基準、定数を抑制、ステップの最大回数、変数の欠損値を平均値で置き換え
- 適合度: R2乗値、調整済みR2乗値、Schwarz Bayesian基準、赤池情報基準(AIC)
因子分析・主成分分析
- 推定方法: 主成分分析、主因子、アルファ因子法、イメージ因子法、最尤法、重みなし最小二乗法、一般化最小二乗法
- 回転手法: バリマックス、エカマックス、クォーティマックス、プロマックス、直接オブリミン
- 表示: 共通性、固有値、寄与率、回転前の因子負荷、回転後の因子負荷、因子変換行列、因子間の相関行列
- 因子得点: 回帰、Bartlett、Anderson-Rubin、因子得点係数行列
- 統計: 1変量の記述統計量、相関行列、KMO適合度測度、Bartlettの球面性検定、残差相関、因子得点係数行列
- グラフ: スクリープロット、因子負荷プロット
階層クラスター分析
- 連結手法: 最近隣法、最遠隣法、グループ間平均連結法、重心法、メディアン法、Ward法
- 所属クラスター: クラスター番号を新しい変数として保存
- 距離行列を保存し、他のプロシージャーで使用
- 表示: クラスター凝集経過工程、所属クラスター、距離行列
- グラフ: クラスター解の水平/垂直つららプロット、デンドログラム
K-Meansクラスター(大規模ファイルのクラスター分析)
- 距離測定: 平方ユークリッド距離
- 初期クラスター中心: 大きく離れたケース、最初のK個のケース、直接指定
- 所属クラスター: クラスター番号を新しい変数として保存
Two-Stepクラスタ分析
- 距離測定: 対数尤度、平方ユークリッド距離
- 使用変数: カテゴリ変数、連続変数、連続変数の標準化
- 所属クラスター: クラスター数を自動判定、クラスター番号を新しい変数として保存
- クラスタ化の基準: BIC、AIC
- クラスター結果: シルエット係数、クラスタプロフィール
判別分析
- 統計: 固有値、分散のパーセント/累積パーセント、正準相関、Wilksのラムダ、カイ二乗検定
- ステップワイズ: F値(除去)、許容度、最小許容度、F値(投入)
- オプション: 1変量のF比、BoxのM検定、非標準化正準判別関数、分類結果表、分類関数係数
- 出力: ステップごとの表示、要約形式での表示、あるいはその両方
- 分類過程: 事前確率、等確率、ケースの割合、ユーザー指定
- ケースごとの結果をシステム・ファイルに保存し、将来の分析で使用
- 解を新しいケースに適用: あるいは将来の分析で使用
- ジャックナイフ法による誤分類率の推定
検定力分析
- 平均(1サンプルのt検定、独立サンプルのt検定、対応サンプルのt検定、一元配置分散分析)
- 比率(1サンプルによる2項検定、対応サンプルによる2項検定、独立サンプルによる2項検定)
- 相関(Pearsonの積率、Spearmanランク順、偏相関)
- 回帰分析(1変量の線型回帰)

メタ分析
- 連続型アウトカム(生データ、事前計算された効果サイズ)
- 2値アウトカム(生データ、事前計算された効果サイズ)
- メタ回帰
データハンドリング
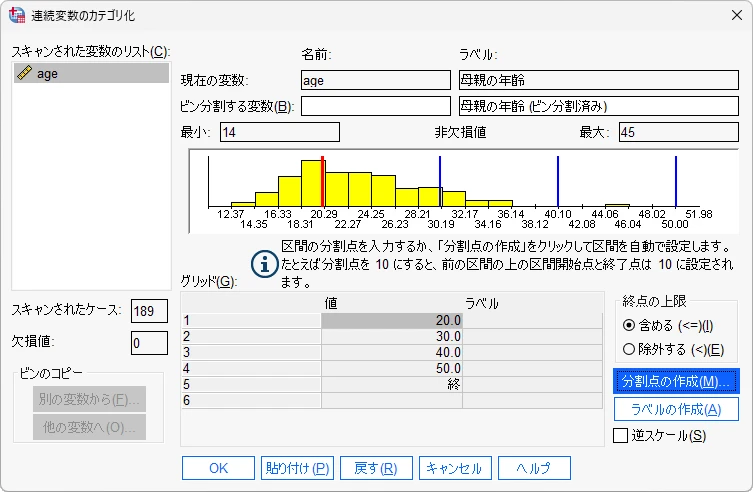
- 連続変数のカテゴリ化:
連続変数の分割点を適切に指定、分割点に基づいて自動的に値ラベルを作成 - 出力管理システム(OMS):
SPSS Statisticsの出力をデータファイルに記録 - 変数プロパティーの定義:
変数ラベル、値ラベル、変数の型、測定の尺度などの設定補助 - データプロパティーのコピー:
あるデータセットから他のデータセットに簡単に辞書情報をコピー - ケースの並び替え:
ケースの並び替え、複数変数をキーとしたケースの並び替え - データの再構成:
縦持ち形式と横持形式の変換、行列の入替 - 新しいユーザー指定の属性:
その変数がどのように変換されたかを説明する情報を使用して作成 - 変数とケース数の上限:
アプリケーション上の制限なし - 日付と時刻ウィザード:
文字列から日付/時刻変数を作成、個々の日付/時刻単位を抽出、日付や時刻を計算 - システム欠損を選択、あるいは各変数ごとに最大3つのユーザー定義欠損値を設定
- 最大半角120文字までの値ラベルを作成
- 最大半角256文字までの変数ラベルを作成
- 変数およびケースの挿入と削除
- ファイルの分割:
サブグループごとの分析やデータ操作 - ケースの選択:
最初のnケースを処理、ケースの無作為選択、ケースのサブセットを選択、乱数シードの指定 - ケースの重み付け:
選択された変数の値でケースに重み付け - ケースのランク付け
- グループ集計:
グループごとに連続変数の要約統計量の集計やサマリーデータファイルの作成 - シンタックスを使用してストリングの長さや変数の型を変更
- ファイル結合:
異なるデータセットの変数やケースの統合 - 変数の計算:
計算式や関数、IF条件などの組合せにより既存変数の変換や新規変数の作成