SPSSのケース識別変数(ID)の追加
ケースを識別するIDを追加する手順
IBM SPSS Statisticsには、データセットの各ケースにIDを付与する関数があります。IDとは、従業員番号や顧客番号など個々のケースを識別するコードです。IDによりデータソースとStatisticsのどのデータが対応しているかを確認できるほか、ファイル結合や再構成などのデータ加工にも必要になるため、データファイルには各ケースにIDを付けることが推奨されます。
ケースを特定できるIDがあれば、並び替えを行った後のデータセットでもケースを識別することができ、IDで並び替えを行うことで元の並び順に戻すことも簡単です。この例では、データセットの1行目から整数値を振ったID変数を追加してみます。新しい変数を作成する場合は、変換メニューに含まれる「変数の計算」を利用します。
1Statisticsでケース識別変数(ID)を追加する方法
システム関数「$CASENUM」の使用
各ケースにIDを付与する場合は$CASENUMシステム関数が便利です。この関数はケースに連番を振ります。
変数の計算で$CASENUM関数を指定
- 「変換」メニュー > 「変数の計算」を選択します
- 「目標変数」ボックスに「ID」と入力します
- 「数式」ボックスに「$CASENUM」と入力します
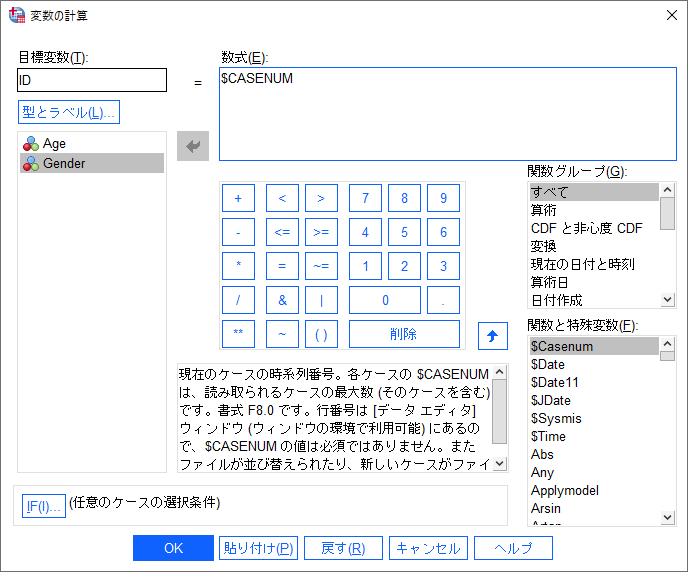
システム関数は「関数グループ」の「すべて」の一覧に含まれていますので、手入力ではなくダブルクリックでも指定可能です。なお、関数名は、大文字と小文字を区別しないため、大文字でも小文字でも機能します。
変数の計算の実行
- 「OK」ボタンをクリックして「変数の計算」ダイアログボックスを閉じます
データファイルの右端に新規変数としてIDが追加され、1行目から順番に整数が振られます。この変数をID(識別)変数として利用することができます。新規作成された変数はデフォルトで小数2桁までの表示となりますので、必要に応じて変数ビューで変数の定義を変更してください。なお、変数の並び順は列見出しをドラッグすることで簡単に移動可能です。
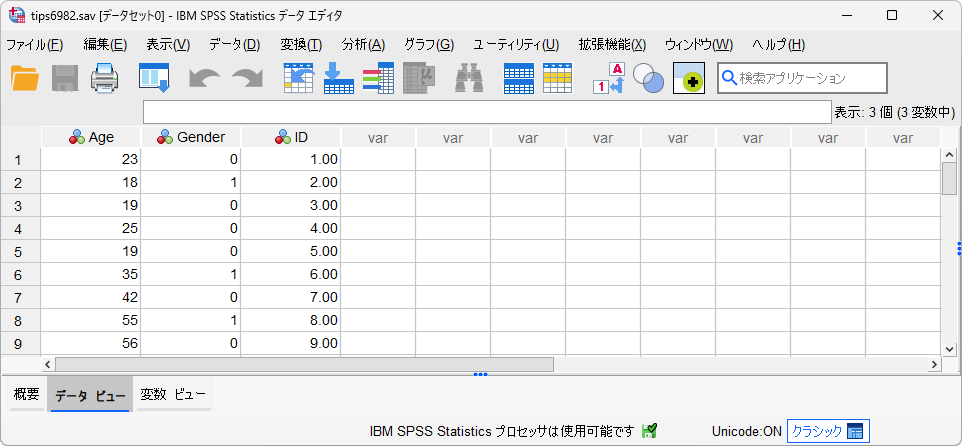
このようにケース番号を識別するID変数を追加することで、並び替えを行ったデータセットでのケースの特定を行うことができるほか、複数のファイルを結合する際のキーとして用いたり、データの再構成(縦持ちデータを横持ちデータに変換する、ロングデータをワイドデータに変換する)を行ったり、傾向スコアによるマッチングを行う際の識別変数として使用したりすることができるようになります。
ケースを識別するIDは非常に重要な変数ですので、多くの場合、Excelやデータベースなど元データファイル側で保持していることが多いですが、IDの変数が含まれていない場合は、このように、SPSSで連番を表す変数を追加することができます。目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
参考文献
- IBM_SPSS_Statistics_Base.pdf
