Cluster Analysis
- 分析手法の種類
- 予測する
- 要因を探る
- 比較する
- 分類する
- 集計する
- 可視化する
類似するレコードを分類
クラスター分析は、データをいくつかのグループ(クラスター)に分類するための手法です。主な目的は、同じクラスターに属するデータが互いに似ており、異なるクラスターに属するデータは異なる特徴を持つようにすることです。クラスター分析は、マーケティングで顧客をセグメント化したり、生物学で種の分類を行ったりする際など、さまざまな分野で使用されます。主成分分析や因子分析が列を分類するのに対して、クラスター分析では通常は行(レコード)を分類します。
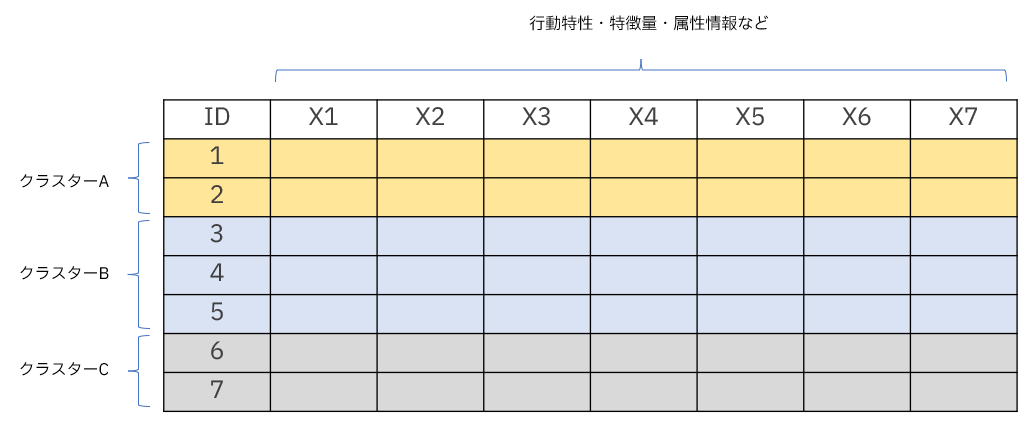
クラスター分析には、大きく分けて階層的クラスター分析と非階層的クラスター分析という2つの手法があります。
階層的クラスター分析(Hierarchical Clustering)は、クラスターを階層的に構築する方法です。この手法では、データ間の距離や類似度を基に、データを次第に集約していくことで、ツリー状の階層的な構造を作ります。この階層構造は、デンドログラムと呼ばれる樹形図で視覚化され、どのクラスターがどのように結合されたかを示します。階層的クラスター分析の利点は、クラスターの数を事前に指定する必要がないことです。一方、計算量が多く、特に大規模なデータセットでは実行に時間がかかることが課題です。
非階層的クラスター分析(Non-hierarchical Clustering)では、クラスターの数を事前に指定し、データをその数のクラスターに分割します。最も一般的な手法はk-means法で、k個のクラスターの中心を基にデータを繰り返し再割り当てし、各クラスターが最適化されるように調整します。非階層的クラスター分析の利点は、計算量が少なく大規模データセットにも対応しやすいことです。ただし、クラスターの数を事前に決める必要があり、初期のクラスター中心の設定によって結果が異なることもあります。
結果の解釈とプロフィール作成
クラスター分析の結果の解釈は、クラスター間の違いを理解し、データの背後にある要因を特定するプロセスです。各クラスターの特性を整理したクラスターのプロフィールを作成することで、どのようなグループが存在し、それぞれにどのような特徴があるのかを明確にします。プロフィール作成で重要なのは、データの背景や専門領域の知識や経験です。
クラスターの数、使用する変数を探索的に変更しながら、仮説に適合するクラスターや新たな知見を提供するクラスターを分析します。クラスターのプロフィール作成は、クラスター分析の結果を他者に伝える際にも有用であり、データの背後にあるパターンや関係性を明確にするための重要です。
ソフトウェア
SPSSでは基本機能のBaseのみでクラスター分析が可能です。非階層的方法として、k-meansやTwo-Stepの手法が使用できます。Rではstatsパッケージが利用でき、より高度な手法や可視化を行う場合にはclusterやfactoextraが便利です。さらに、クラスター数を決定するためにはNbClustが役立ちます。Pythonではscikit-learnライブラリ等を使用します。前処理や可視化にはpandasやseabornが効果的です。
参考文献
- Jain, A. K., Murty, M. N., & Flynn, P. J. (1999). Data clustering: A review. ACM Computing Surveys, 31(3), 264-323.
- 石村友二郎,石村貞夫(2022),SPSSでやさしく学ぶ多変量解析 第6版,東京図書.
- IBM_SPSS_Statistics_Base.pdf