Cross Table
- 分析手法の種類
- 予測する
- 要因を探る
- 比較する
- 分類する
- 集計する
- 可視化する
2つの変数の関係性や差異を比較
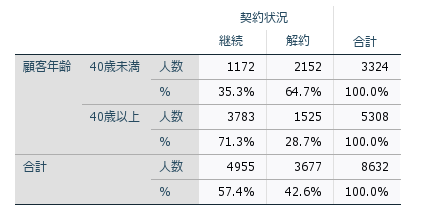
クロス集計表は、行と列に各カテゴリ変数を配置し、交点にその組み合わせに該当するデータの度数を記載します。たとえば、性別と喫煙習慣といった2つの質的変数を扱う場合、それぞれの組み合わせごとの人数やパーセンテージが表示されます。これにより、変数間の関係を一目で理解できるようになります。
セル内には度数や%ではなく、年齢や金額など行と列以外の変数の統計量を指定することもあります。行変数や列変数に連続変数(スケール)を用いる場合は、事前に階級値に区分するなどのデータ加工を行います。
また、行や列に複数の変数を配置したり、入れ子(ネスト)した多重クロス集計表などでより多くの情報を提示することができるようになります。セルの内容の基本は、度数やパーセンテージですが、量的変数の平均値や95%信頼区間、標準偏差や四分位数などを表現することもできます。
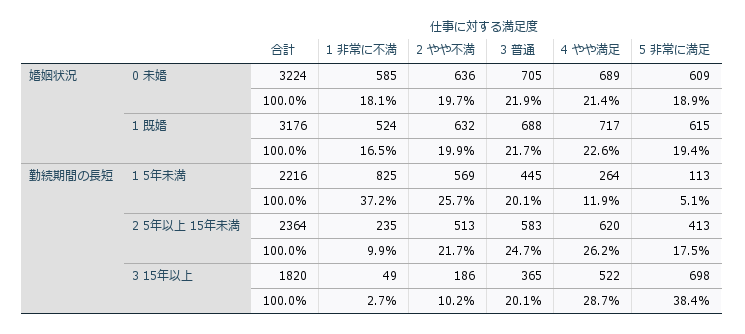
統計的検定として、独立性の検定(カイ2乗検定やFisherの直接法)、McNemar検定、Mantel-Haenszelなどが利用でき、2×2クロス集計の場合はオッズ比 Odds Ratio, OR の計算も行われます。また、行と列の関係の強さを測るためには、φ係数やクラメールVなどがの連関係数(coefficient of association)が利用されます。
要因分析に利用する場合、目的変数に対する要因が1つのみになるため、単変量解析(univariate analysis)とも呼ばれます。多数の要因に基づいた分析を行いたい場合は、多変量解析(multivariate analysis)が必要となり、ロジスティック回帰分析やディシジョンツリーなどの手法が適用可能です。
クロス集計表は、データ分析の基礎的な手法であり、データの特徴を把握するための第一歩として非常に重要です。また、分析結果を報告する際にも、結果を簡潔に伝えるための道具として利用されます。
ソフトウェア
SPSSでは、基本機能のBaseで対応しています。Rでは、table()関数を使ってクロス集計表を作成します。デフォルトのままだとシンプルすぎて見にくい場合がありますが、ftable()、knitr::kable()、formattable、gtなどのツールを使うことで見やすくすることが可能です。Pythonでは、pandasライブラリのcrosstab()関数を使ってクロス集計表を作成します。
参考文献
- 対馬 栄輝(2016),SPSSで学ぶ医療系データ解析,東京図書
- 滋賀大学データサイエンス学部(2024),この1冊ですべてわかる データサイエンスの基本,日本実業出版社
- IBM_SPSS_Statistics_Base.pdf
- IBM_SPSS_Custom_Tables.pdf