CHi-squared Automatic Interaction Detector
- 分析手法の種類
- 予測する
- 要因を探る
- 比較する
- 分類する
- 集計する
- 可視化する
有意検定に基づく決定木の手法
CHAIDは、ディシジョンツリーの手法の1つで、カイ2乗検定に基づく交互作用(Interaction)の自動検出アルゴリズムです。購買予測や解約分析、リスク分析などに利用できます。医療統計でも適用可能ですが、数十程度のサンプルサイズではデータセットをセグメントに分割することができない場合が多く、少なくとも100を超えるサンプルサイズを必要とします。統計解析や機械学習の手法としてよく利用されます。基本的にはカテゴリ型の従属変数を対象としますが、スケール(連続型)型の従属変数を対象とすることもでき、その場合の代表値は平均値となりF検定(分散分析)に基づく方法になります。
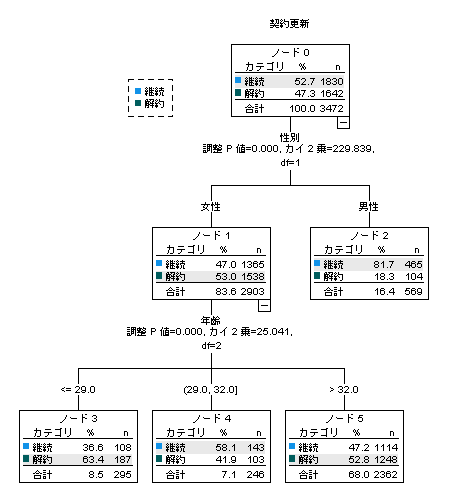
この例では、契約更新の有無(従属変数/目的変数/アウトカム)を性別や年代の要因によって分割しています。男性より女性のほうが解約しやすく、女性のなかでも29歳以下と32歳より高い年齢の解約率が高いようです。カテゴリ変数の分割にはカイ2乗統計量が用いられます。変数の選別に多くの仮説検定が実行されることになるため、SPSSでは検定の多重性の問題への対処としてBonferroni調整がデフォルトで行われます(上図の調整P値がBonferroni調整P値です)。また、分岐のルールはモデル検証(validation)の上、予測ルールとして使用できます。
また、SPSS Modelerにはインタラクティブツリーの機能が含まれており、分岐に使用する変数を自由に指定したり、カテゴリ変数の結合や連続変数の分割点などを柔軟に指定したカスタマイズツリーを構築することもでき、ビジネスルールや分析上の仮説などをツリー図に反映させることも可能です。
ソフトウェア
SPSSでは、Decision Treesオプションで決定木分析の各手法に対応します。なお、SPSS Modelerの方が機能が充実しており予測に使用する場合に向いています。Rでは、rpartパッケージを使用します。Pythonでは、sklearnのDecisionTreeClassifierやDecisionTreeRegressorを使用してCRTを実装できます。
参考文献
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth International Group.
- 滋賀大学データサイエンス学部(2024),この1冊ですべてわかる データサイエンスの基本,日本実業出版社
- IBM_SPSS_Decision_Trees.pdf