non-parametric test
- 分析手法の種類
- 予測する
- 要因を探る
- 比較する
- 分類する
- 集計する
- 可視化する
特定の分布を仮定しない検定
ノンパラメトリック検定は、データが特定の分布(例として正規分布)に従わない場合でも適用できる統計的手法です。パラメトリック検定がデータの分布に関する仮定に依存するのに対し、ノンパラメトリック検定はそのような仮定を必要としないため、データの性質に柔軟に対応できます。これにより、正規性が確認できないデータや、サンプルサイズが小さい場合でも有効です。
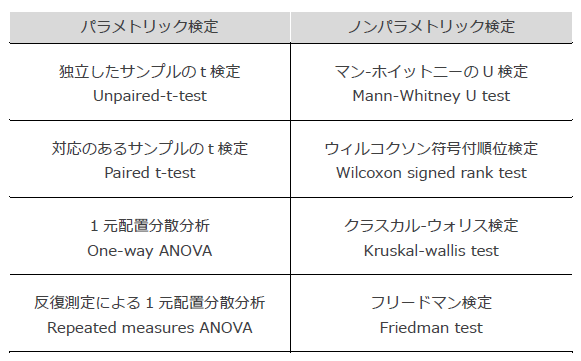
ノンパラメトリック検定は、ランク(順位)を基に比較を行うことが多く、外れ値や極端な値の影響を受けにくいのが特徴です。例えば、データがカテゴリカルデータである場合や、測定尺度が順序尺度である場合でも使用可能です。元のスケール尺度がランクに変換されることで、情報量が失われる側面があります。これは、テストの「得点」で分析するのか「順位」で分析するのかの違いのイメージです。
また、ノンパラメトリック検定はパラメトリック検定に比べて、検定力(有意な差を検出する力)が低いことがあるため、データの分布に問題がない場合は、できる限りパラメトリック検定を使用することが推奨されます。
ソフトウェア
SPSSでは、標準のBaseの機能で多くのノンパラメトリック検定に対応します。代表的な検定として、マンホイットニーのU検定、ウィルコクソンの符号順位検定、クラスカル・ウォリス検定、コクランのQ検定などが用意されています。GUIを通じて簡単に設定でき、結果もグラフィカルに表示されます。Rでは、ノンパラメトリック検定をコマンドベースで実行します。Rには多くの統計パッケージがあり、ノンパラメトリック検定に関連する関数が充実しています。例えば、wilcox.test() 関数でマンホイットニーのU検定やウィルコクソンの符号順位検定を実行できます。Pythonでは、主にSciPyライブラリを用いてノンパラメトリック検定を実行します。Pythonのスクリプトによって、多様な検定が簡単に実装できます。
参考文献
- 永田靖,吉田道弘(1997),統計的多重比較法の基礎,サイエンティスト社
- 大久保街亜,岡田謙介(2012),伝えるための心理統計: 効果量・信頼区間・検定力,勁草書房
- 対馬 栄輝(2016),SPSSで学ぶ医療系データ解析,東京図書